
Sınıflandırma algoritmalarını kullanarak yapılan çalışmalarda en büyük yanılgılardan biri başarı kriteri olarak sadece doğruluk oranına bakmaktır. Özellikle dengesiz veri setlerinde (imbalanced data sets) doğruluk oranı bize pek bilgi vermez. Dengesiz veri seti sınıflar arasındaki dağılımın yakın olmadığı veri setlerini tanımlarken kullanılır.
Düşünün ki 10.000 kişiden alınan çeşitli özniteliklere bakarak bu kişilerin kanser olup olmadığını tahmin etmek istiyorsunuz ve içlerinde 10 kişi gerçekten kanser. Biz herkese sağlıklı dersek
Accuracy (Doğruluk) = (9.990/10.000) * 100= %99.9
Kanserli hastaları tespit etmeden yapılan rastgele bir tahminin doğruluk oranı bile muazzam. Benzer problem telekom ve kredi kartı dolandırıcılıkları tespitinde de görülmektedir. Anomali ve dolandırıcılık vakalarının bütün veri setine oranı oldukça düşüktür. Bu gibi durumlarda doğruluğa ek olarak iki metriğe daha bakmakta fayda var: recall (duyarlılık) ve precision (kesinlik). TP, FP, TN, FN metriklerinin ne olduğundan ve confusion matrixten bahsedeyim.
TP (True positive — Doğru Pozitif): Hastaya hasta demek.
FP (False positive — Yanlış Pozitif): Hasta olmayana hasta demek.
TN (True negative — Doğru Negatif): Hasta olmayana hasta değil demek.
FN (False negative — Yanlış Negatif): Hasta olana hasta değil demek.
CONFUSION MATRIX
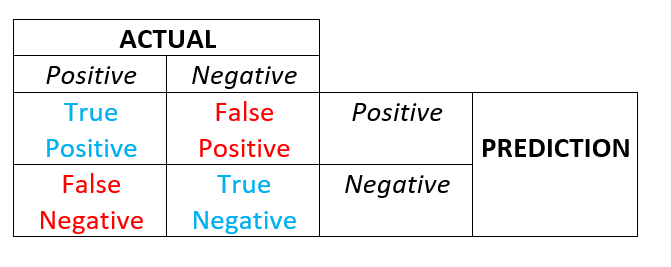
Genel çerçeveyi gördüğümüze göre yukarıda bahsettiğim iki metriğin ne olduğuna bi bakalım.
Recall (Duyarlılık): Hasta olanları doğru tespit etme oranı?

Artısı: Bazı anomali vakalarını doğru tespit etmek yanlış alarm üretmekten daha önemli. Diğer bir deyişle false negative false positiveden daha kritik. Kanserli birini tespit edemeyip ölümüne neden olmaktansa kanser olmayan biri için yanlış tahmin yapıp onu hastaneye çağırmak daha kabul edilebilir.
Eksisi: Herkesi hastaneye çağırdık (recall = 1) bütün kanserli vakaları bulduk ama alarmların çoğu yanlış (FP yüksek)
Precision (Kesinlik): Hasta dediklerimizin gerçekten kaçı hasta?
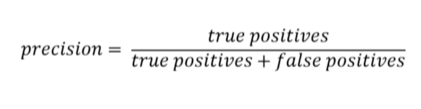
Artısı: Birine hasta demeden önce iyice düşünüp taşınmamızı sağlıyor. Herkes hasta dersek precision = 10/10.000 = 0.001
Eksisi: Eğer bir kişiye hasta dedik ve o kişi gerçekten hasta (precision = 1) ama kalan 9 kişiyi tespit etmedik. (FN yüksek)
Gördüğünüz gibi recall ve precision iki önemli metrik ve aralarında bir trade-off var. Bununla baş edebilmek için F1-skoru kullanılıyor. F1-skoru ekstrem durumları cezalandırmak için aritmetik ortalama yerine harmonik ortalamayı kullanıyor.
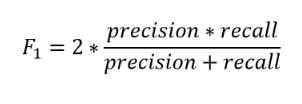
Hatırlarsanız ilk tahminimizde herkese sağlıklı demiştik ve accuracy (doğruluk) oranımız %99.9'du ama tahminin recall ve precision oranları 0.
ROC Curve (Receiver Operating Characteristic Curve - Alıcı İşletim Karakteristik Eğrisi)
Sınıflandırma modellerinin başarı hesaplarında ROC Curve sık sık karşımıza çıkmaktadır. İlk başta karışık gelebilir temelde iki basit metriğe bakıyor.

TPR: Kanser olan insanlara hangi olasılıkla doğru diye alarm veriyorum. (Recall aslında)
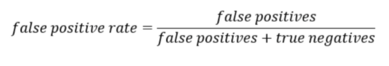
FPR: Kanser olmayan insanlara hangi olasılıkla yanlış alarm veriyorum. (Bu metrik yeni daha önce görmedik.)
Bu iki metriği x ve y eksenlerine yerleştirerek çizginin altında kalan alanı hesaplıyoruz (AUC — Area Under Curve).
Aşağıdaki görselde her eğri bir modeli temsil ediyor. Eğri boyunca düşen threshold (sınır) değerlerine karşı TPR ve FPR oranları tespit ediliyor (o noktalar eğriyi oluşturuyor aslında.)
Her threshold için precision, recall değerlerini hesaplayıp F1 skorunu maksimum yapan thresholdu seçiyoruz.
Rastgele bir sınıflandırma (Random Classification) yapıldığında çizginin altında kalan alan 0.5 olmakta. Çizginin altında kalan alan ne kadar büyükse modelin başarı oranı o kadar yüksek demektir. Aslında bir modelin F1 skorune kadar yüksekse çizginin altında kalan alan da o kadar yüksek deyip işin içinden kolayca sıyrılabiliriz.
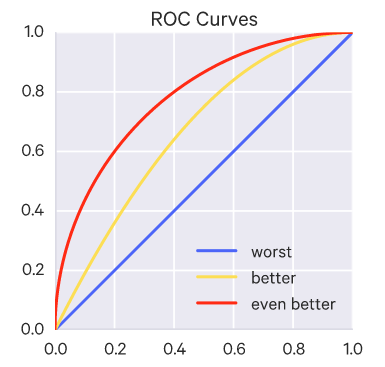
Şimdiye kadar bahsettiğim metriklerdeki problem FP ve FN durumlarına eşit yaklaşmasıdır. Halbuki kredi kartı dolandırıcılığını tespit edememek (FN) yanlış tespit yapıp müşteriyi aramaktan (FP) daha büyük maliyet içerir. Bununla başa çıkmak için çeşitli yöntemler var:
FN = k * FP (örneğin k = 3). Böylece FN durumunun FP durumundan 3 kat daha problemli olduğunu modele ekleyebiliriz.
Buradaki yeni problemimiz ise her FN durumunu aynı görmektir. Halbuki 5.000 TL değerinde bir dolandırıcılıkla 50 TL değerindeki dolandırıcılık veya standart bir müşteriyle premium müşterinin kartında gerçekleşen dolandırıcılığın maliyeti banka açısından aynı değildir.
Başarı oranlarını büyük gösteren ama gerçekte hem istatistiksel hem de ekonomik olarak anlamsız çalışmalar yerine problemi ve alanı doğru anlayıp ona göre modeller kurmalıyız.
Çalışmanın Medium versiyonuna şuradan ulaşabilirsiniz.
Sorunuz olursa bana Linkedin veya Twitter hesaplarından yazabilirsiniz.
