
2018
Python ile Zaman Serisi Analizi 2
Geçmiş verilere bakarak gelecek hakkında tahminler yapmak finans ve iş analitiğinin en önemli konularındandır. Önümüzdeki ay için x hissesinin değerini tahmin etmek, y semtinde ne kadar elektrik-su tüketileceğini veya depoda ne kadar z ürününden bulunması gerektiğini kestirebilmek ilk akla gelen tahminleme konularındandır.
2018
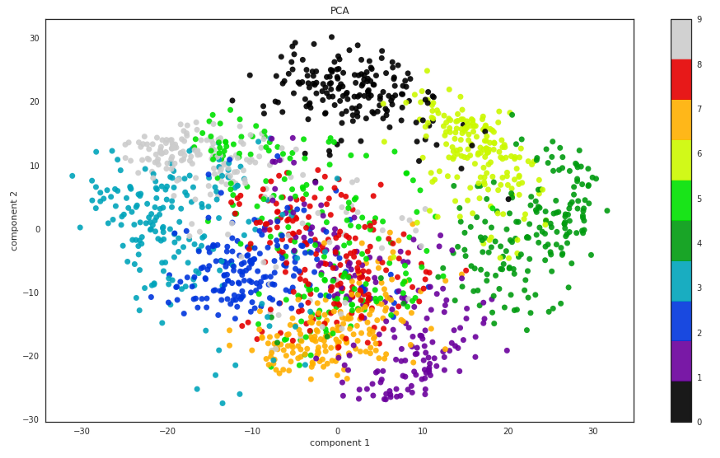
Boyut Azaltma PCA
Boyut küçültmenin en kolay yolu verimizi en iyi tanımlayan öznitelikleri bulup diğerlerini atmak (öznitelik seçimi — feature selection). Örneğin 100 boyuttan 10 tanesinin önemli olduğuna ulaşıp kalan 90 özniteliği atmak ama bu tahmin edeceğiniz gibi bilgi kaybına sebep oluyor. Bizim uğraşmamız gereken şey ise öznitelik çıkarımı (feature extraction)yapmak -en az bilgi kaybıyla boyut küçültmek-. Bunu yapmak için verideki dağılımın maksimum varyansını-bilgisini tutan minimum sayıda değişken oluşturuyoruz. Eğer bir değişken her örnek için aynı değere sahip ise gereksiz bir değişkendir biz en yüksek varyansa sahip olan değişkenleri bulmalıyız.
2018
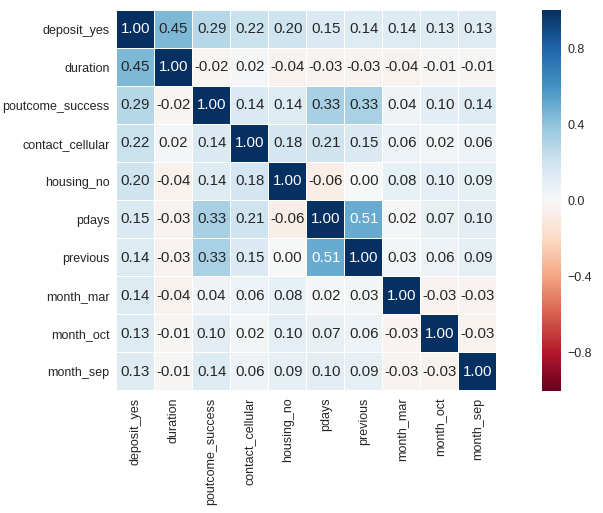
ML Modellerinde Hiper parametre Seçimi
Hiper-parametre seçimi (hyper-parameter tuning) elinizle radyo frekansı ayarlamaya benziyor. Hani ses iyidir ama siz bi tık daha iyi olmasını istersiniz ve milimetrik parmak dokunuşları yaparsınız ya işte hiper-parametre seçimi de makine öğrenmesi modelleri için o işe yarıyor. Örnek veri seti olarak elimizde Portekiz bankasından alınmış 11 bin kişinin yaşı, mesleği, medeni durumu, ev kredisi alıp almadığı, son görüşmeden sonra geçen zaman, görüşmenin sabit telefonla mı cep telefonuyla mı gerçekleştiği gibi öznitelikler var. Kişilerin bankaya depozito yatırıp yatırmayacağını tahmin eden bir model kurmaya çalışıyoruz. Çıkacak sonuçlara göre belirli kişilere ve gruplara kişiselleştirilmiş pazarlama yöntemleri uygulanabilir.
2018
Veri Bilimi 2018 Trendleri
Bu yazıyı veri bilimine ilgi duymaya başlayan fakat bu yolun nereden başlayıp nereye gittiğini tam olarak kestiremeyen meraklıları için elimden geldiğince basit olarak yazmaya çalıştım.

2018
Anaconda ve PySpark Kurulum
Anaconda, Python ve R dilleri için veri bilimi ve makine öğrenmesiyle ilgili kütüphanelerin yönetimini ve kurulumunu kolaylaştıran ücretsiz bir dağıtımdır. Windows, Linux, ve MacOS’la uyumlu çalışan ve 6 milyondan fazla kullanıcısı olan Anaconda 250'den fazla popüler veri bilimi ve makine öğrenmesi kütüphanesine sahiptir.

2018
Python PySpark Benzer Fonksiyonlar
Bu yazıda veri analizinde sıkça kullanılan Python fonksiyonlarının PySpark karşılıklarından bahsedeceğim.

2018
Python ile Zaman Serisi Analizi 1
Zaman serisi, düzenli zaman aralıklarında alınan veri noktalarının oluşturduğu seriye verilen isimdir.[1] Zaman serisi analizi zamansal ölçümlerin yapıldığı her alanda kullanılmaktadır. Bunlardan ilk akla gelenler: istatistik, ekonometri, finans, sinyal işleme, hava ve deprem tahmini…

2018
Overfitting-Underfitting-Cross Validation
Overfitting probleminde model çalıştığımız veri seti üzerinde harika sonuçlar verir (training error düşük) fakat hiç görmediği yeni veri setleri üzerinde başarısız tahminler yapar. (test error yüksek) Yukarıda örneğini verdiğim gibi bütün soruları ezberlemek modelimizi çok kompleks hale getiriyor ve gürültü (noise) barındırıyor. Biz eğitim setindeki değişkenlerin arasındaki gerçek ilişkiyi modellemeye çalışıyoruz sadece o veri setine özgü gürültüyü değil.

2018
Sınıflandırma Modellerinde Başarı Kriterleri
Sınıflandırma algoritmalarını kullanarak yapılan çalışmalarda en büyük yanılgılardan biri başarı kriteri olarak sadece doğruluk oranına bakmaktır. Özellikle dengesiz veri setlerinde (imbalanced data sets) doğruluk oranı bize pek bilgi vermez. Dengesiz veri seti sınıflar arasındaki dağılımın yakın olmadığı veri setlerini tanımlarken kullanılır.
