ML Modellerinde Hiper-parametre Seçimi
Hiper-parametre seçimi (hyper-parameter tuning) elinizle radyo frekansı ayarlamaya benziyor. Hani ses iyidir ama siz bi tık daha iyi olmasını istersiniz ve milimetrik parmak dokunuşları yaparsınız ya işte hiper-parametre seçimi de makine öğrenmesi modelleri için o işe yarıyor.
Örnek veri seti olarak elimizde Portekiz bankasından alınmış 11 bin kişinin yaşı, mesleği, medeni durumu, ev kredisi alıp almadığı, son görüşmeden sonra geçen zaman, görüşmenin sabit telefonla mı cep telefonuyla mı gerçekleştiği gibi öznitelikler var. Kişilerin bankaya depozito yatırıp yatırmayacağını tahmin eden bir model kurmaya çalışıyoruz. Çıkacak sonuçlara göre belirli kişilere ve gruplara kişiselleştirilmiş pazarlama yöntemleri uygulanabilir.
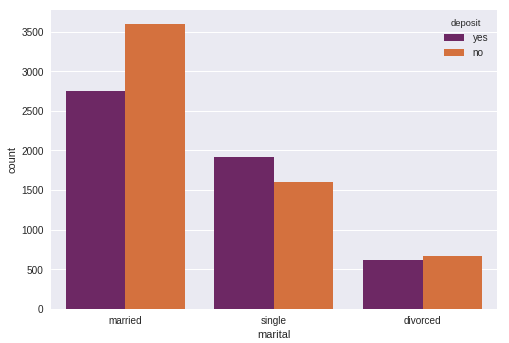
Bekar insanların %50'den fazlası bankada vadeli para tutarken evli insanlar için durum pek iyi değil gibi.
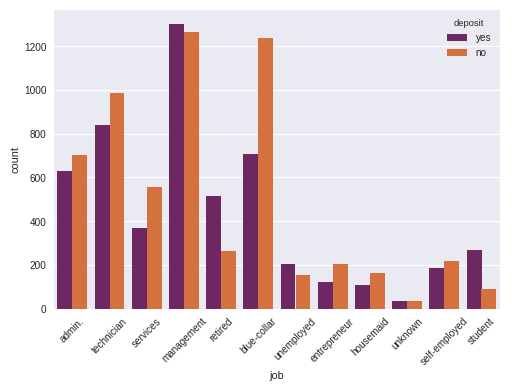
Yukarıdaki tabloda meslek dağılımlarına göre kişilerin bankaya vadeli para yatırıp yatırmadıklarını görüyoruz. Örneğin mavi yakalılarda durum hiç açıcı değil. Buradan hareketle farklı pazarlama kampanyaları düşünülebilir.
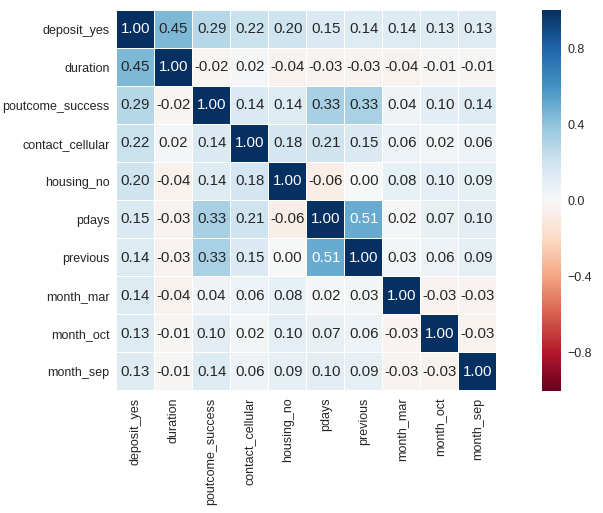
Son olarak depozita yatırmakla diğer değişkenler arasındaki korelasyona bakmak istiyorum. One-hot-encoder yöntemiyle kategorik değişkenleri binary (0,1) hale getiriyorum aksi halde makine ne cinsiyeti ne medeni durumu ne de iş güç hiçbir şey anlamaz.
Gördüğünüz gibi satır sayısı 17'den 53'e çıktı. Sakın korkmayın bilgisayarlar için bu boyutlarda işlem yapmak hala çok kolay.
53*53 bir korelasyon matrisine bakmak pek mümkün değil onun için depozito yatırmakla en yüksek korelasyonu olan 10 değişkeni seçiyorum.
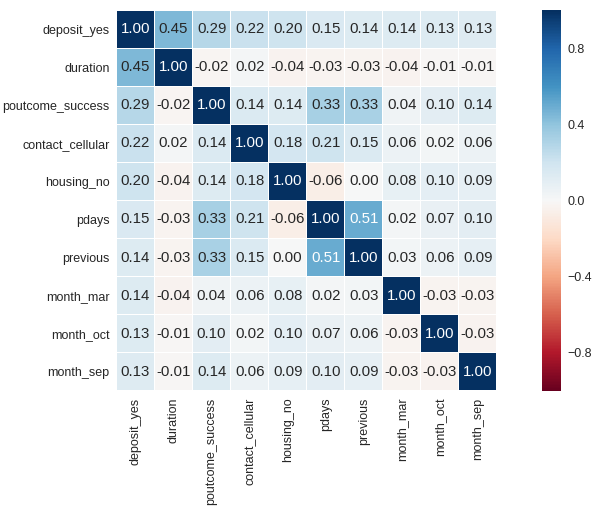
Depozito yatırmakla en yüksek pozitif korelasyonu olan 5 öznitelik
- Son telefon konuşmasının uzunluğu (son konuşmanın süresi 0'sa kişi telefonda ikna edilmemiştir, o yüzden çok iyi bir öznitelik olmayabilir.)
- Bir önceki pazarlama kampanyasının başarılı sonuç vermesi.
- Konuşmanın sabit telefon yerine cep telefonu ile gerçekleşmesi.
- Ev kredisi alınmaması.
- Son kampanyadan beri geçen sürenin artması. (Her gün her gün aramak bıktırıyor haliyle.)
analizi burada kesmeyin unutmayın korelasyon nedensellik anlamına gelmez. “correlation does not imply causation!”
Bu yazının konusu hiper-parametre seçimi olduğu için açıklayıcı veri analizi kısmını burada bitiriyorum ama gördüğünüz gibi sadece veriyi analiz ederek bile harika bulgular elde ediyoruz.
Hedef değişkenimizi tutuyoruz. Sonrasında veri setimizi train ve test setlerine ayırıyoruz, buraya kadar her şey oldukça basit şimdi random forest modelimizi kuralım.
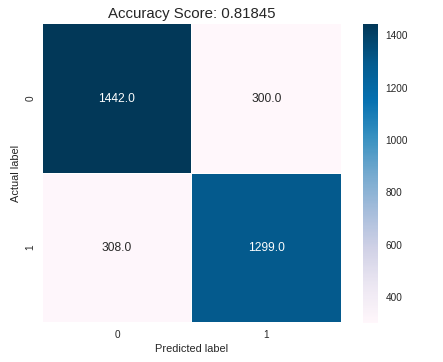
Sonuçlar hiç de kötü değil. Hiç görmediğimiz bir veri setinde %81.8 olasılıkla doğru tahminler yapıyoruz. Geçen hafta öğrendiğimiz cross-validation metodunu uygulayalım şimdi de.

Modelin 5 farklı eğitim ve test veri setindeki ortalaması %82.4 yani az önce şans eseri %81.8 gibi bir doğruluk oranı yakalamadık modelimiz gayet iyi çalışıyor.
Daha gidecek yol var mı bi bakalım…

GridSearch bizim için 500 farklı kombinasyonu deneyerek en iyi sonuçlar veren hiper-parametreleri seçti. (max_depth:9, max_features:12)
Bu hiper-parametreler kurularak bir model kurulduğunda en iyi doğruluk oranı %85.2, bizim ilk modeli kurduğumuz eğitim ve test veri setindeki doğruluk oranı %84.3. (ilk model: %81.8)
Yukarıdaki adımlar izlenerek diğer makine öğrenmesi modellerinde de basitçe hiper-parametreler bulunabilir.
Örneğin knn için params = {‘knn__n_neighbors’: range(1, 5)} yazarak GridSearchCV yapabilirsiniz.
Çalışmanın Medium versiyonuna şuradan ulaşabilirsiniz.
Sorunuz olursa bana Linkedin veya Twitter hesaplarından yazabilirsiniz.
